Forward
渲染流程
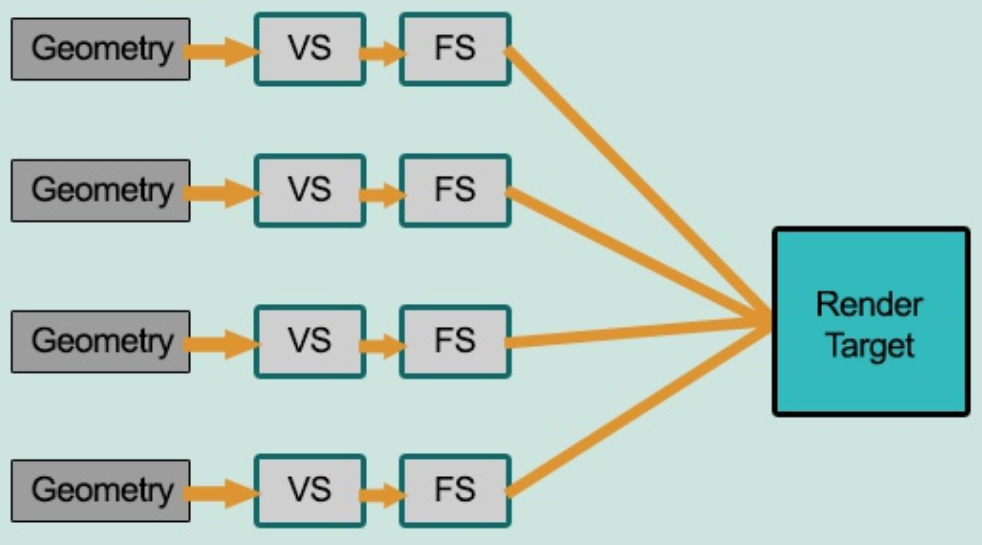
待渲染几何体 → 顶点着色器 → 片元着色器 → 渲染目标
优缺点
缺点
- 光源数量对计算复杂度影响巨大
- 访问深度等数据需要额外计算
优点
- 支持半透明渲染
- 支持使用多个光照pass
- 支持自定义光照计算方式(延迟渲染因为是用整个Light Pass去计算所有的光照,所以不支持每一个物体用单独的光照方式计算)
Deferred
渲染流程
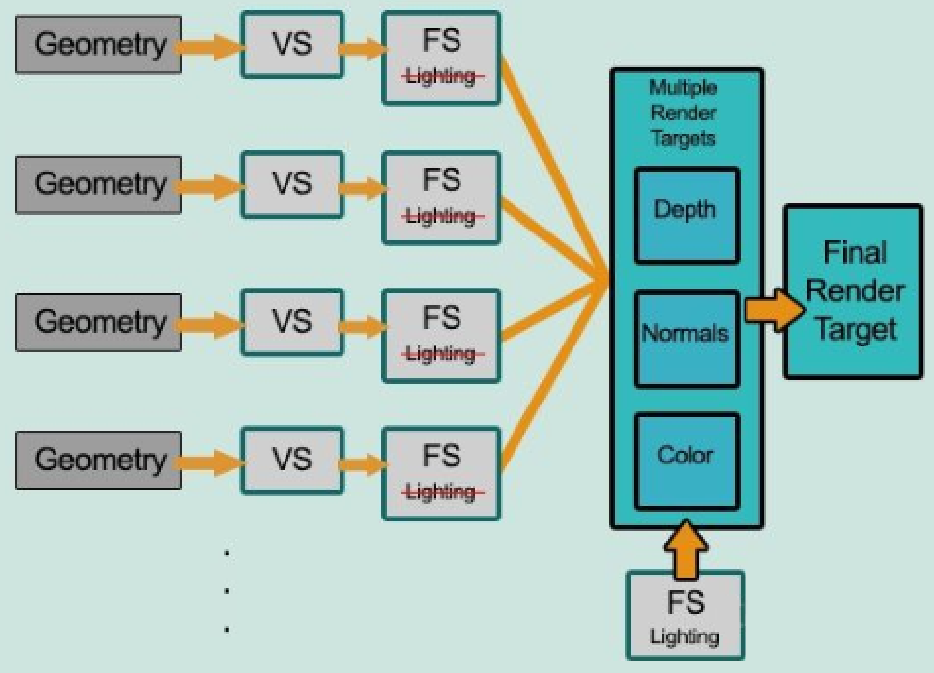
首先将场景渲染一次,获取到的待渲染对象的各种几何信息存储到G-buffer中,然后第二个pass再遍历所有G-buffer中的位置、颜色、法线等参数,执行一次光照计算。
一个典型的G-Buffer:

优缺点
缺点
- 对MSAA支持不友好
- 透明物体渲染存在问题
- 占用大量的显存带宽
优点
- 大量光照场景优势明显
- 只渲染可见像素,节省计算量
- 对后处理支持良好
- 用更少的shader
Forward+
渲染流程
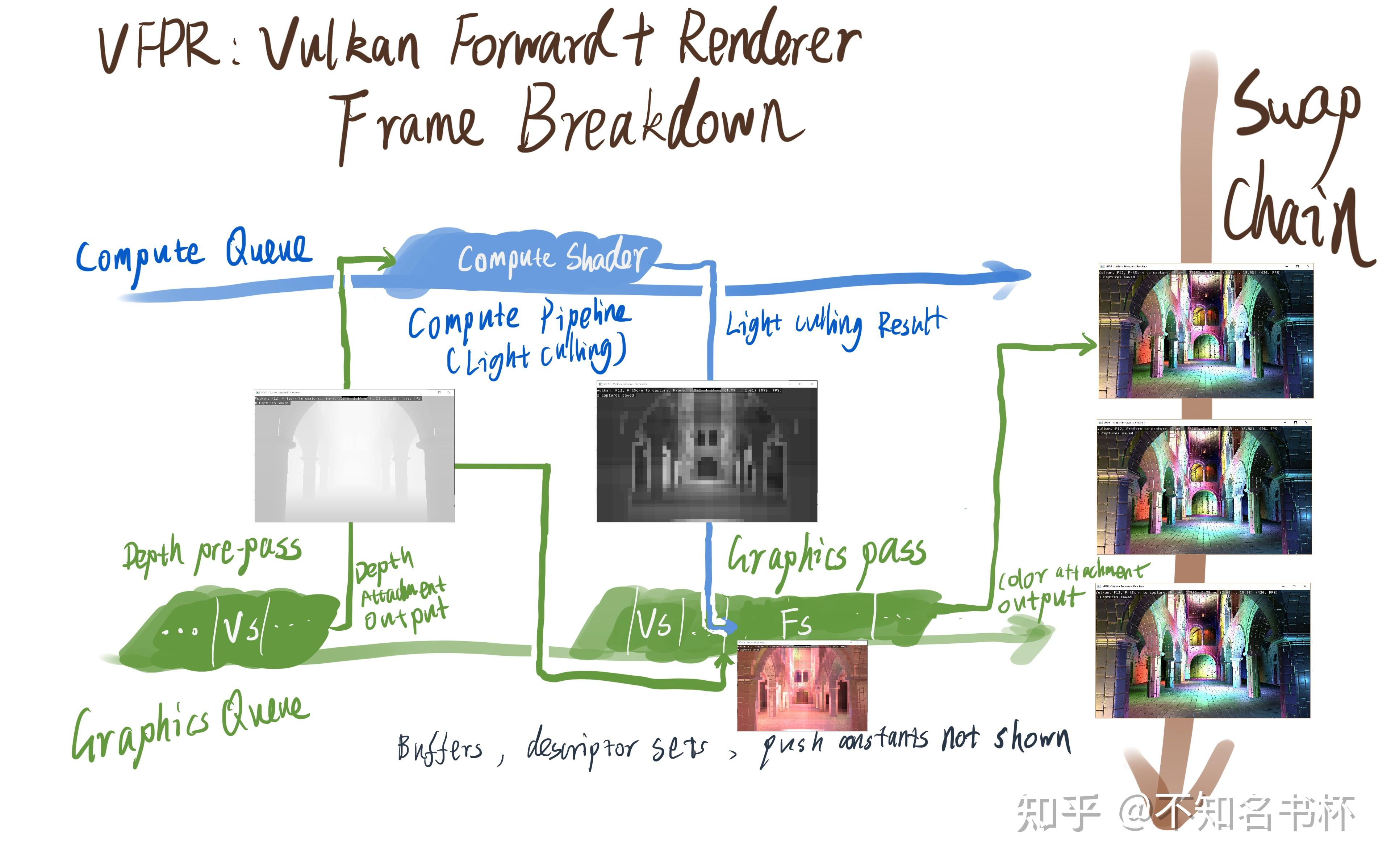
| |
Depth PrePass
只渲染深度,相当于 Z-Prepass,因此其实也可以结合 HiZ 或者 Early-Z 来。
Light Culling
全程在 GPU Compute Shader 中完成,分为屏幕分块 → Tile 视锥构建 → 光源视锥相交测试 → 光源列表生成四步。
最容易影响整体Forward+效率的阶段也就是Light Culling阶段。
- 屏幕分块(Tile Grid)
- 每个 Tile 对应一个线程组(Thread Group),线程数 = Tile 内像素数(如 16×16=256 线程)
- 为每个 Tile 分配:LightList[MaxLightPerTile](光源索引数组)、LightCount(光源数量)
- 构建 Tile 视锥体(Tile Frustum)
- 每个 Tile 对应一个 3D 视锥体,包含空间范围和深度范围
- 根据 Tile 内最大最小深度,把 Tile 的 2D 屏幕矩形,拉伸为 3D 视锥体
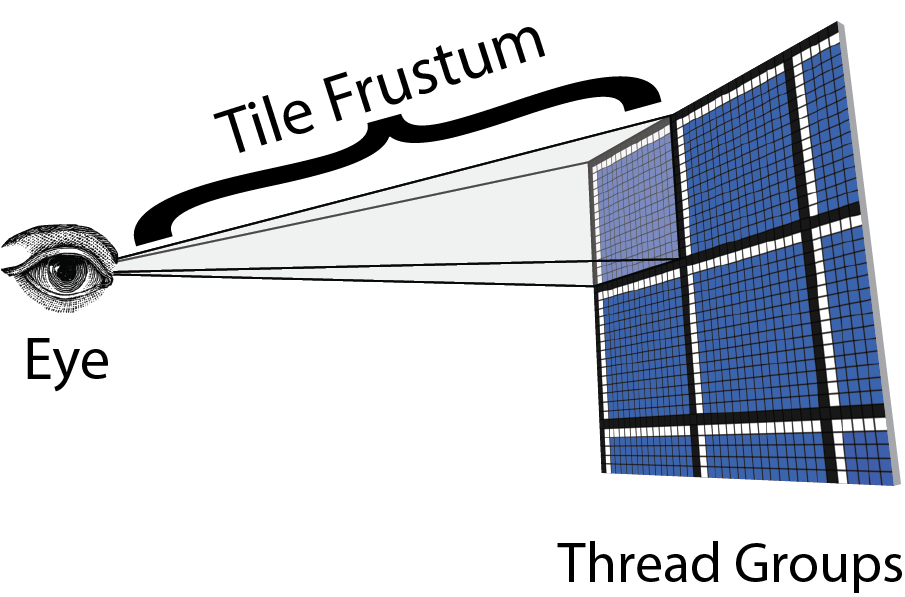
- 光源与 Tile 视锥相交测试
- 点光(Point Light):用球体(Sphere) 表示,中心 = 光源位置,半径 = 光源影响范围。
- 聚光(Spot Light):用圆锥体(Cone)+ 球体 表示。
- 方向光(Directional Light):通常不参与剔除(影响全屏幕),直接加入所有 Tile 的 Light List。
- 光源列表生成与存储
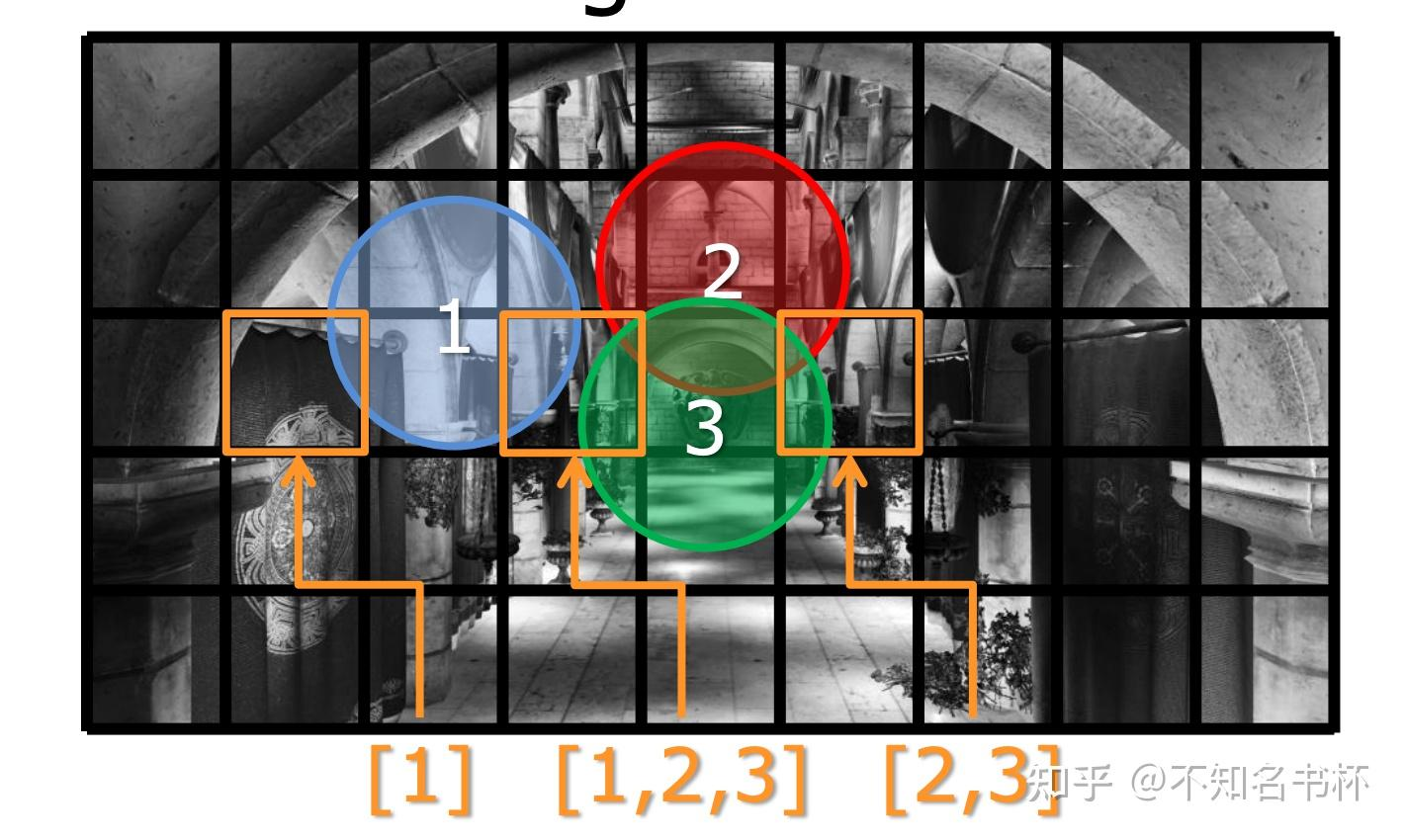
Final Shading
从Light List中获取到影响该像素的光源。然后进行相应的着色计算。
优缺点
缺点
- Light Culling效果不稳定,Light Culling是基于深度u去做的,场景每帧的深度信息都不一样,导致每帧最终生成的light List也是不一样的。
- 寻找minZ和maxZ需要遍历Tile中的像素,有一定的性能消耗,由其是在移动端。并且现在的实现是强依赖Computer Shader,可能兼容性没那么好
- 强制的 early depth test,在某些三角形数量特别多的场景,这个可能会成为瓶颈
优点
- 对多光源的支持
- 有Forward的一切好处(透明物体的支持以及MSAA,复杂材质的支持)
TBR TBDR
移动平台更看重性能功耗比,如果性能只有一半,但功耗只有四分之一,也会考虑采纳。于是移动平台上光栅化往往采用tile-based方案,而不是立即式渲染 Immediate Mode。
https://www.bilibili.com/video/BV1dL4y1c789
渲染流程
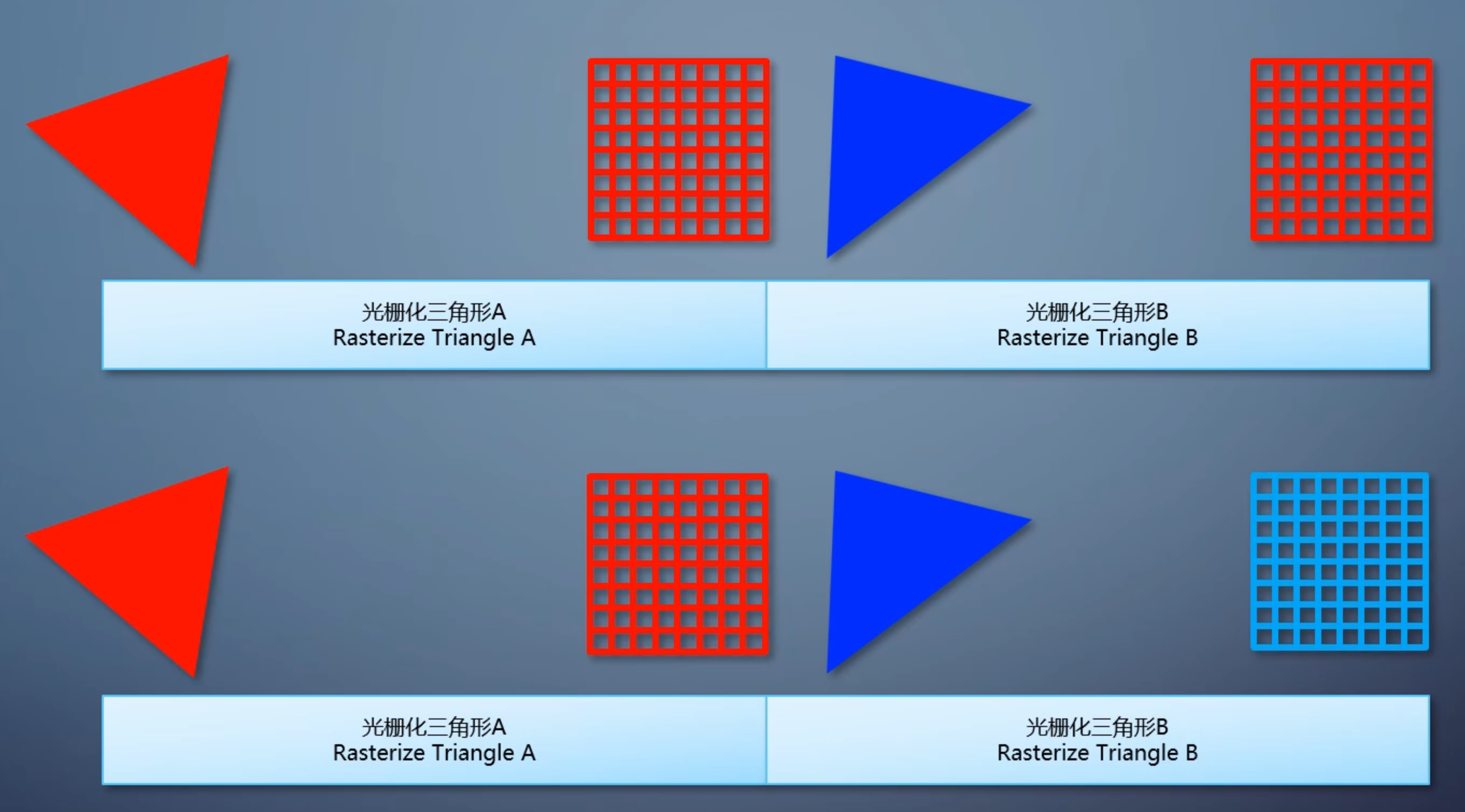
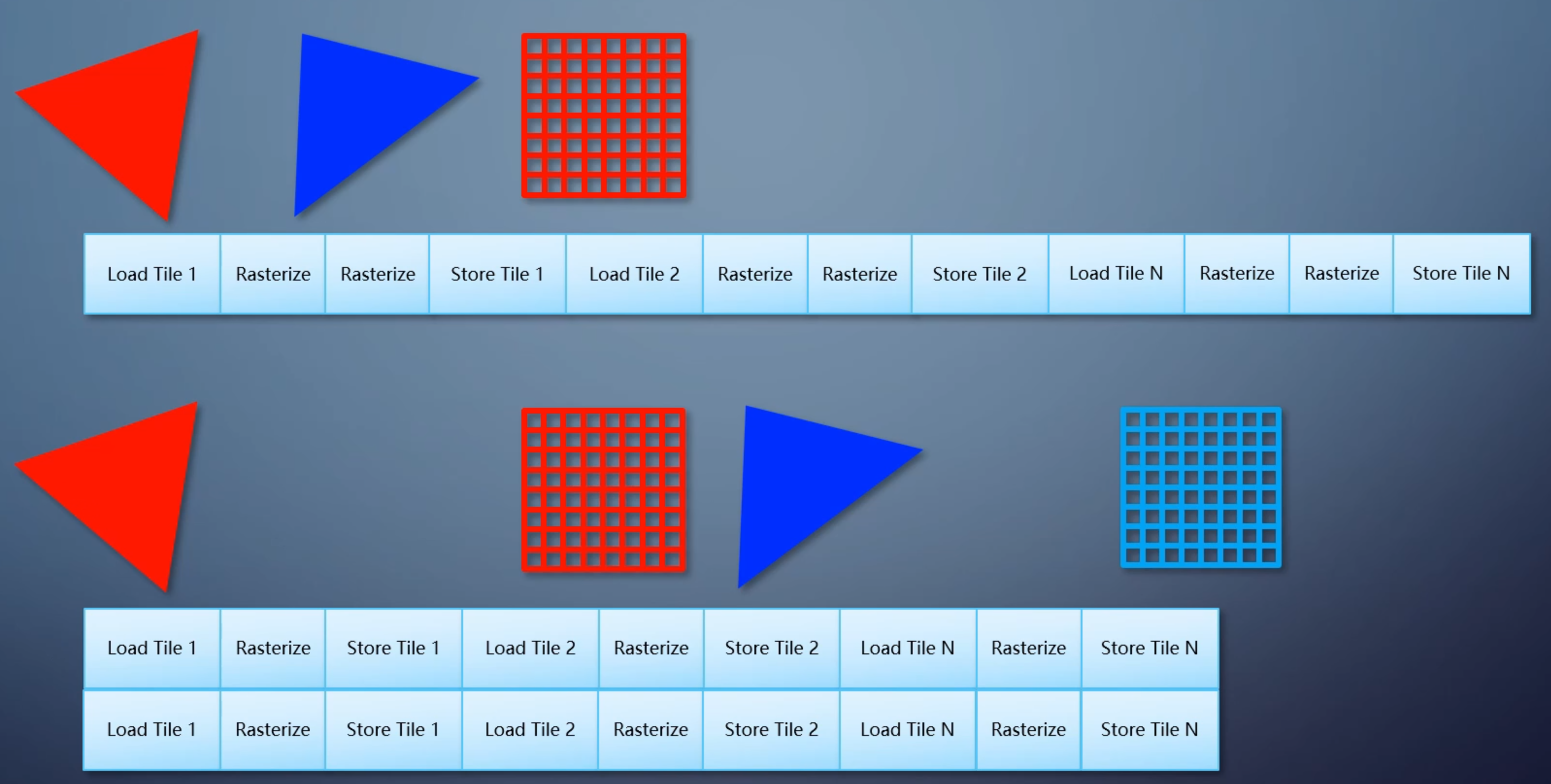
把渲染目标划分为很多固定大小的tile,常见的是32*32.每个 tile 包含一个列表,存有和这个 tile 相交的所有三角形。
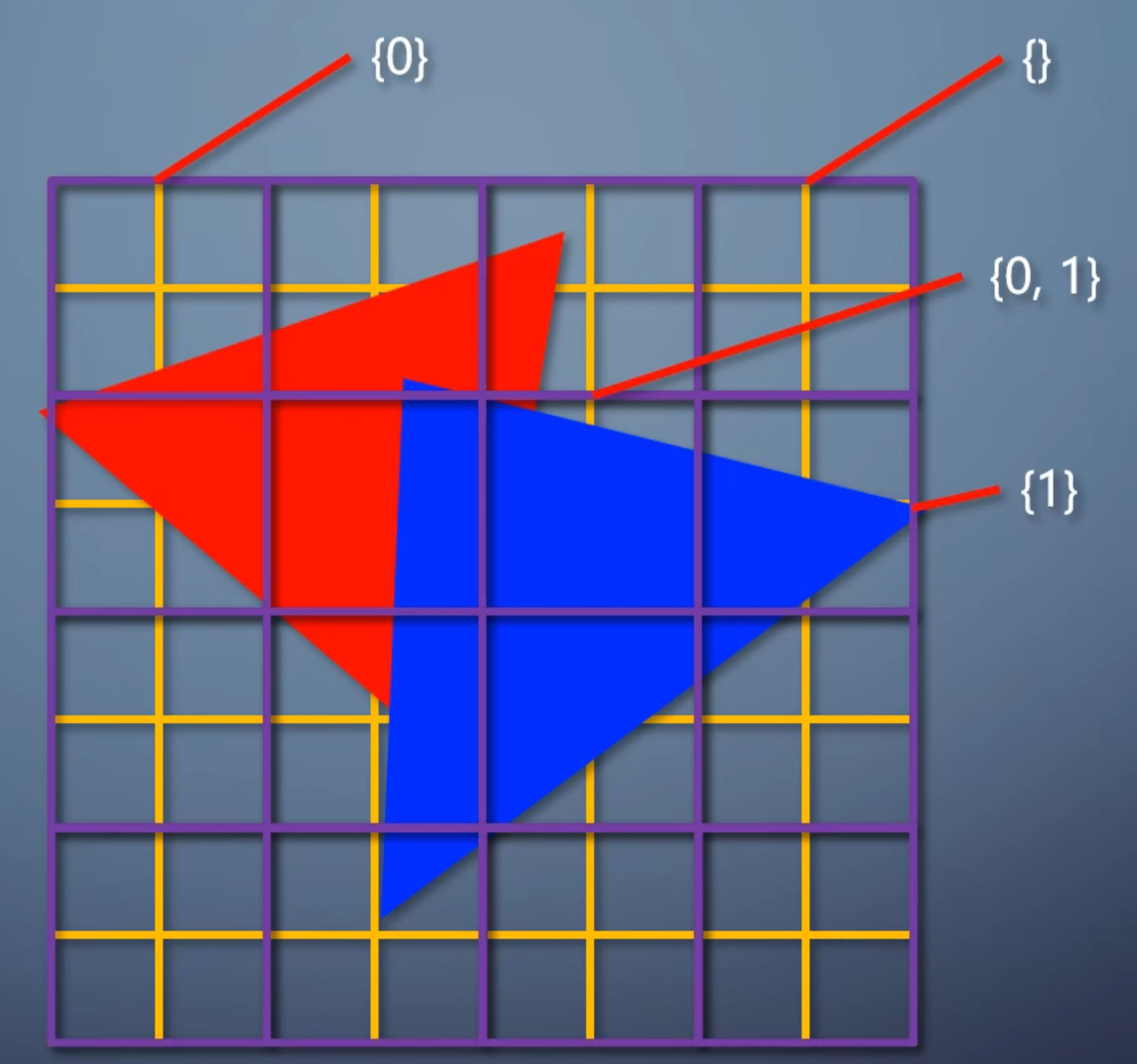
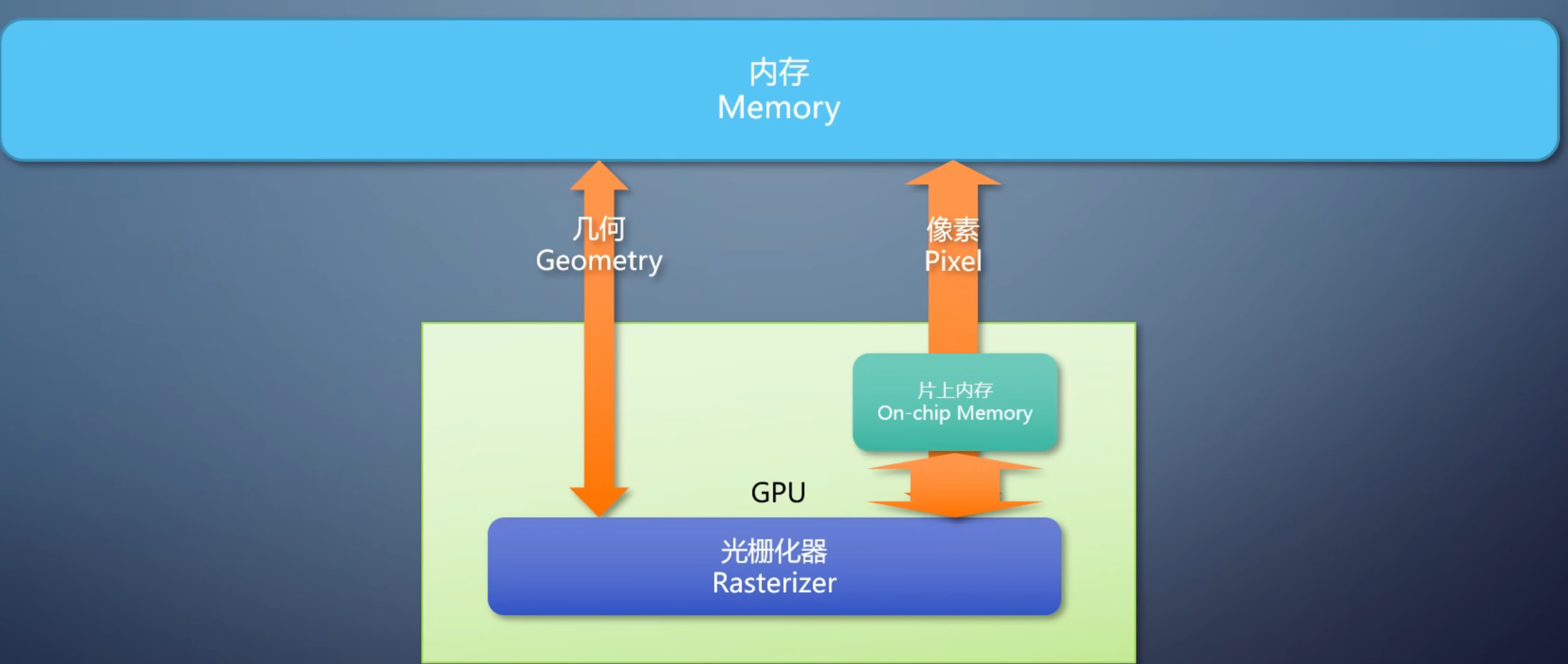
所以 tile-based 光栅化不再是一个一个三角形处理,而是一批一批处理。这样的GPU,需要有一个片上内存充当cache的角色,不需要大,但访问速度远远高于内存。
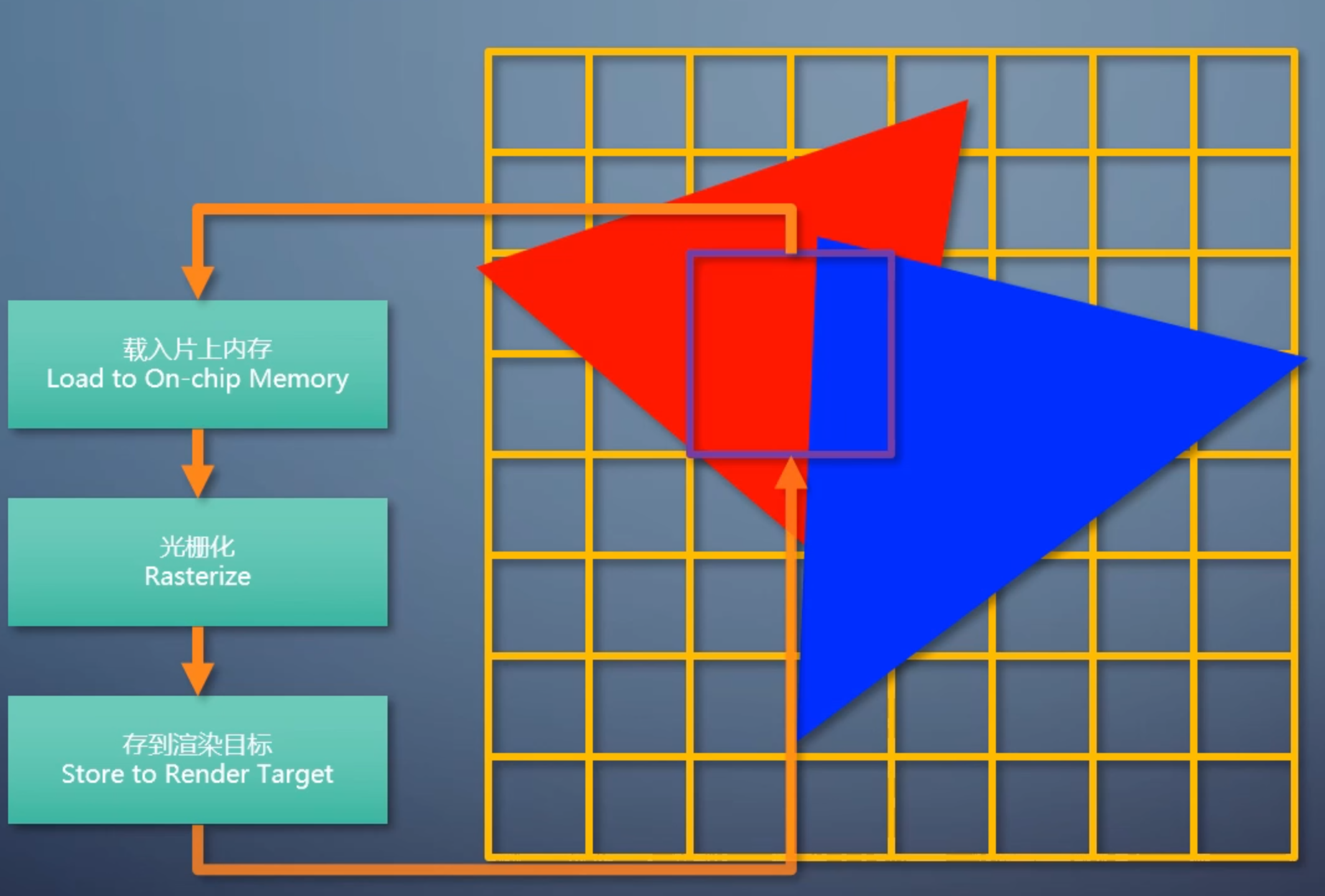
- 对于每个tile,先会把渲染目标的对应区域载入GPU的片上内存
- 接着用扫描线算法,把列表里的三角形都渲染上去
- 最后把片上内存里的结果存到渲染目标
不管三角形如何层层叠叠,每个tile每次对内存的读写总是只有32x32个像素,远低于立即式。但因为一个三角形没法一直填充下去,会因为tile而被打断,性能其实是降低的。只是相比之下功耗降得更多。
TBDR
tile-based deferred rendering
开启深度测试的情况下,在 TBR 基础上增加硬件级隐面剔除(Hidden Surface Removal, HSR),先确定 Tile 内所有可见像素,再统一执行片段着色,被遮挡像素直接丢弃,完全消除 Overdraw。
- 几何阶段(Binning):同 TBR,生成 Tile List。
- 可见性判断(HSR):对 Tile 内所有图元做深度排序与遮挡测试,标记可见像素,丢弃不可见像素。
- 渲染阶段(Tile Processing):仅对可见像素执行片段着色与混合,结果写回帧缓冲。
和立即式渲染的对比
立即式
tile-based
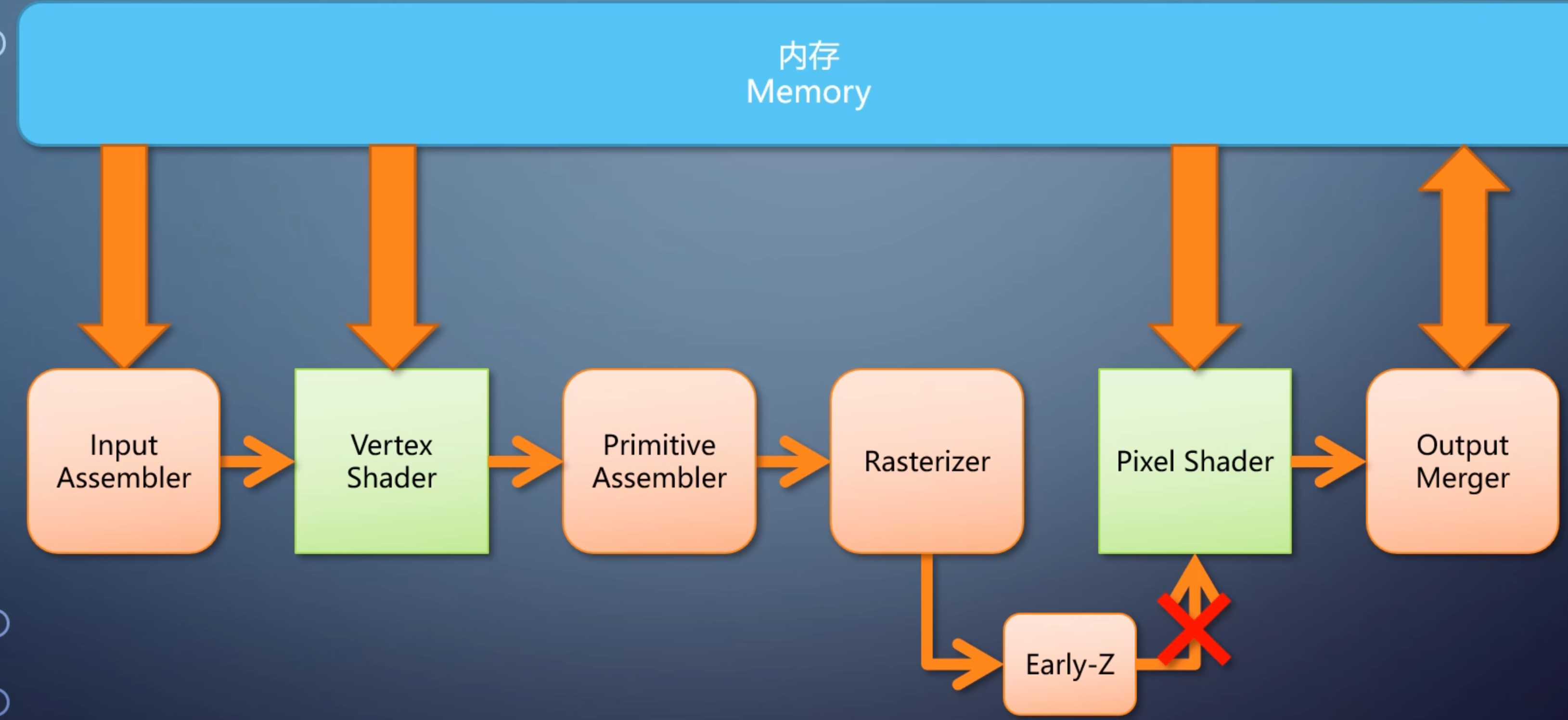
Early-Z
Early Z由硬件实现,随着硬件的演进,它的功能也在不断进化,处理的情况也变多。
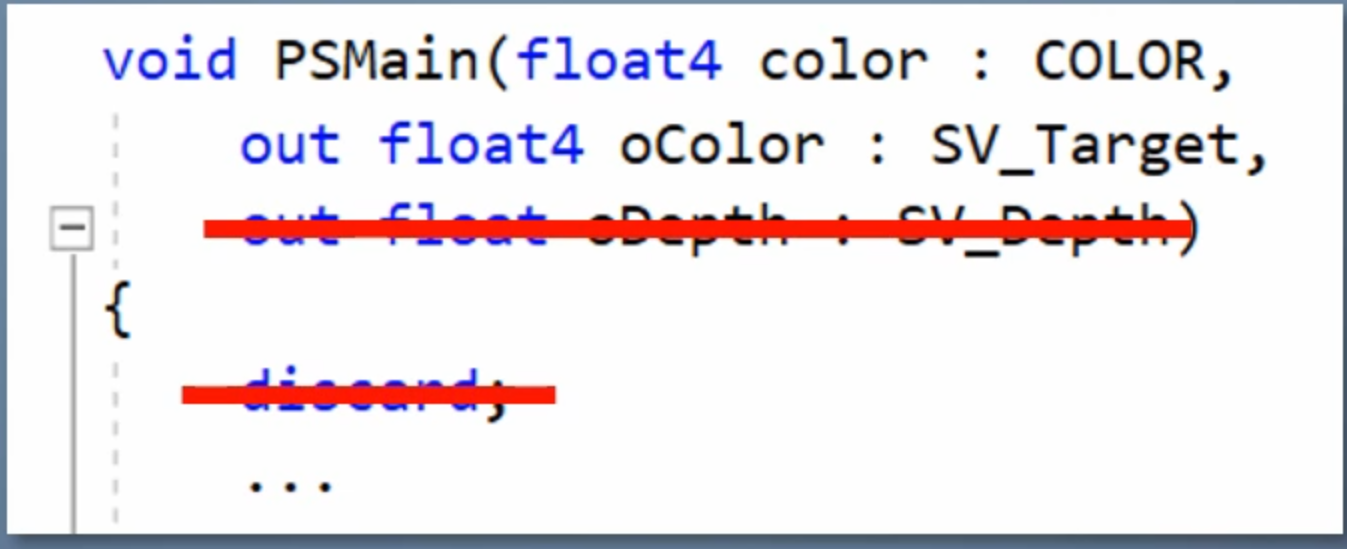
在渲染状态符合条件的情况下,驱动会检查一下pixel shader,如果不输出深度、不用discard丢弃像素,就启用early-z
像素在进入pixel shader之前提前进行一次深度测试,如果已经被挡住就不往下走,直接丢弃掉。
Early‑Z 只有在近的物体先渲染时才能有效遮挡远处物体。若大量物体从远到近渲染,Early‑Z 几乎无法剔除任何像素,Overdraw 依然很高。
Early‑Z 生效的必要条件
要让 Early‑Z 正常工作,必须同时满足:
- ZTest On、ZWrite On
- 片元着色器中无 clip/discard、无 AlphaTest
- 不手动修改深度值(SV_Depth)
- 关闭 Alpha Blend(不透明物体)
- 物体尽量按近→远排序渲染
个人想法:这都是一趟渲染的情况,如果提前做了 preZ 的 pass,提前先写入深度,理论上这里的 5 应该不需要,ZWrite On 也不需要。
参考
https://zhuanlan.zhihu.com/p/408238134
https://zhuanlan.zhihu.com/p/553907076
https://zhuanlan.zhihu.com/p/672881713