本质思考
实时渲染本质上是一个在有限时间预算内,对三维连续场景信号(几何、材质、光照)进行离散化采样(生成屏幕像素),并不可避免地与走样进行斗争的过程。
渲染管线
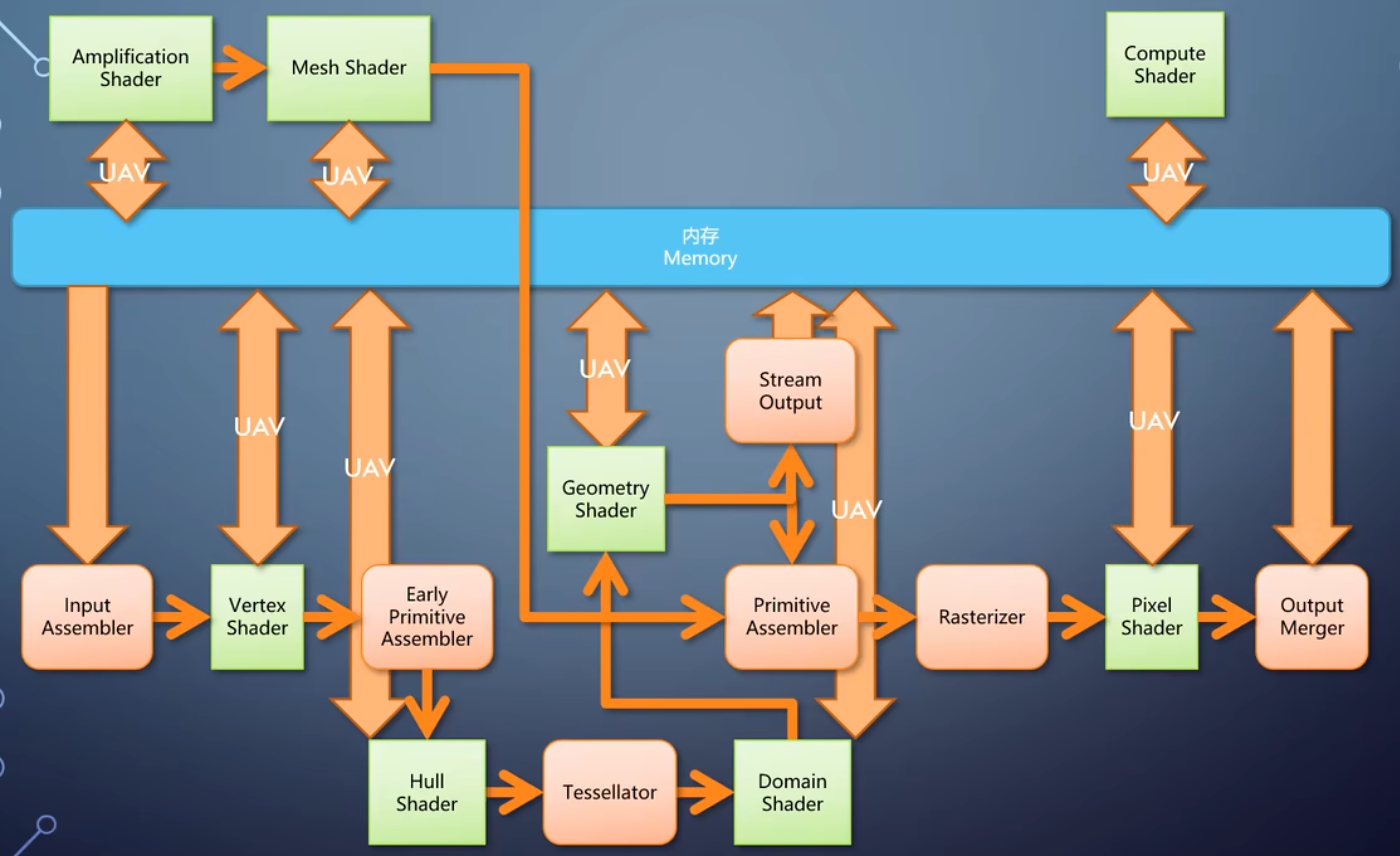
如上图,shader 是可编程部分,其余是固定流水线单元。
Input Assembler 从 Vertex Buffer 里组装出一个顶点送入 Vertex Shader;
Early Primitive Assembler 把顶点组装成 Primitive 送给 Hull Shader(因为只是 Vexter Shader 没有处理 Primitive 的能力,如线、三角形,所以诞生了 Geometry Shader,就把原先的 Primitive Assembler 拆成了两部分;处理 Primitive 最主要的是细分操作,于是单独拆分出 Tessellator 的部分)
Hull Shader 指定每个图元需要如何被细分,比如内部分成多少个,每条线分成多少段。
固定流水线 Tessellator 固定算法来细分。
Domain Shader 根据细分的参数负责计算细分后每个顶点的信息。
Geometry Shader 可以单入多出,一个 Primitive 送入 Geometry Shader 可以输出多个 Primitive,即可以送入 Primitive Assembler 完成整条流水线,也可以直接送入内存。
Primitive Assembler 图元组装单元,把顶点组装成三角形,并把屏幕外的三角形过滤掉,只保留屏幕内的三角形
 后续拆分成两块,前者 Early Primitive Assembler 完成 Primitive 的组装,后者完成剩余事情。
后续拆分成两块,前者 Early Primitive Assembler 完成 Primitive 的组装,后者完成剩余事情。
Rasterizer 计算三角形覆盖哪些像素,把这些像素送入 Pixel Shader 处理。
Output Merger 进行各种测试,并最后写入到渲染目标。
我们希望在少量数据甚至没有数据的时候,也有能力生成数据并送入 Rasterizer 里(Compute Shader 不能接入 Rasterizer), 所以催生出了 Amplification Shader 和 Mesh Shader。
Amplification Shader 负责指定执行多少次 Mesh Shader,Mesh Shader 负责产生几何体。这时渲染单位就不是图元Primitive,而是一小块网格,称为 Meshlet。一个Meshlet送入 Amplification Shader,它可以决定这个 Meshlet 是否需要进一步处理,要则传入到Mesh Shader。
实际渲染中,硬件光栅化的输出并不是一个一个像素,而是一个一个2x2的像素块。这称为一个quad。这样才可以计算任何变量的ddx、ddy。
这四个像素如果有在三角形之外的,之后才会被丢弃。对大三角形来说,最多就是边缘被浪费,但对于小于一个像素的三角形,这就浪费了3/4。因此,对于大量三角形都小于一个像素的时候,构造一个以像素为单位的软件光栅化器,可以避免浪费,性能反而更高。如 UE5 的Nanite。
https://zhuanlan.zhihu.com/p/408238134
https://www.bilibili.com/video/BV1xF411g7Z9
GPU 架构
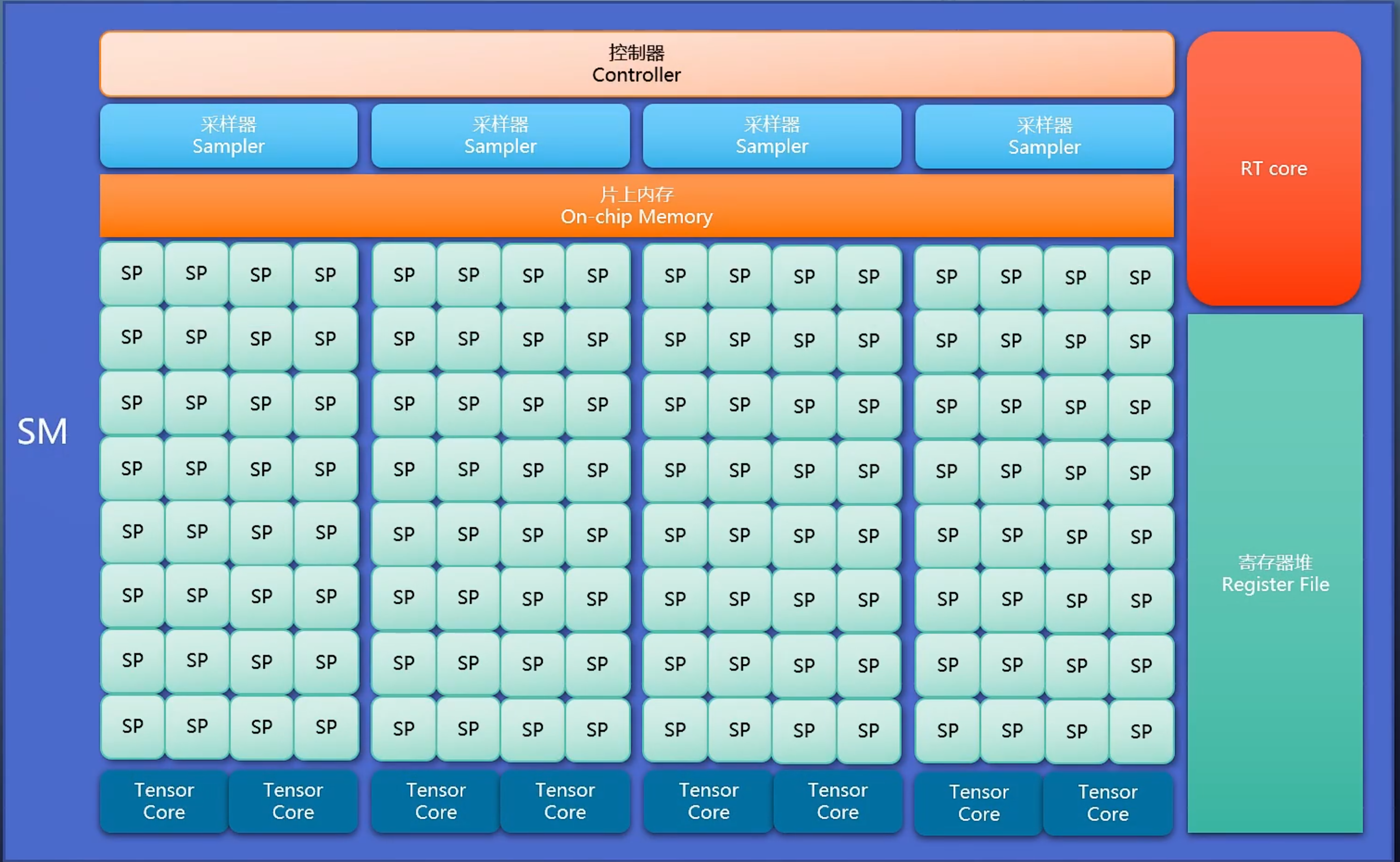
GPU 有多个 SM (Streaming Multi-Processor)。一组SP加上控制器、片上内存等,组成一个功能相对完整的 SM。里面装一堆 Warp 和 SP
Warp(线程束,Nvidia术语,AMD叫 Wavefront),32个线程为一组,一起取指、一起发射,是调度和执行的最小单位
SP(Streaming Processor)跑一个线程,称为一个核,代表单个线程
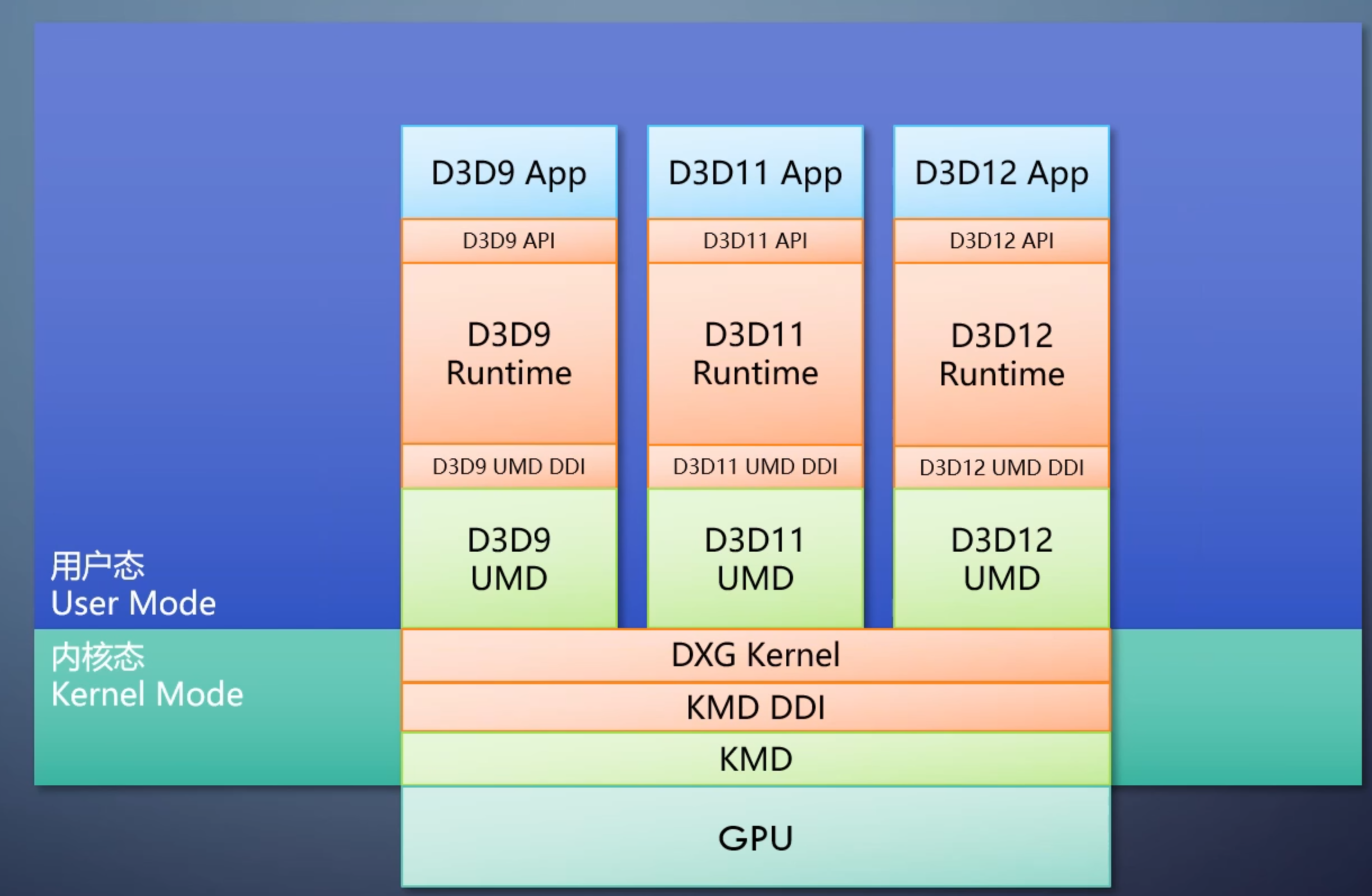
厂商提供的驱动也分为用户态部分 UMD 和内核态部分 KMD,提高稳定性。
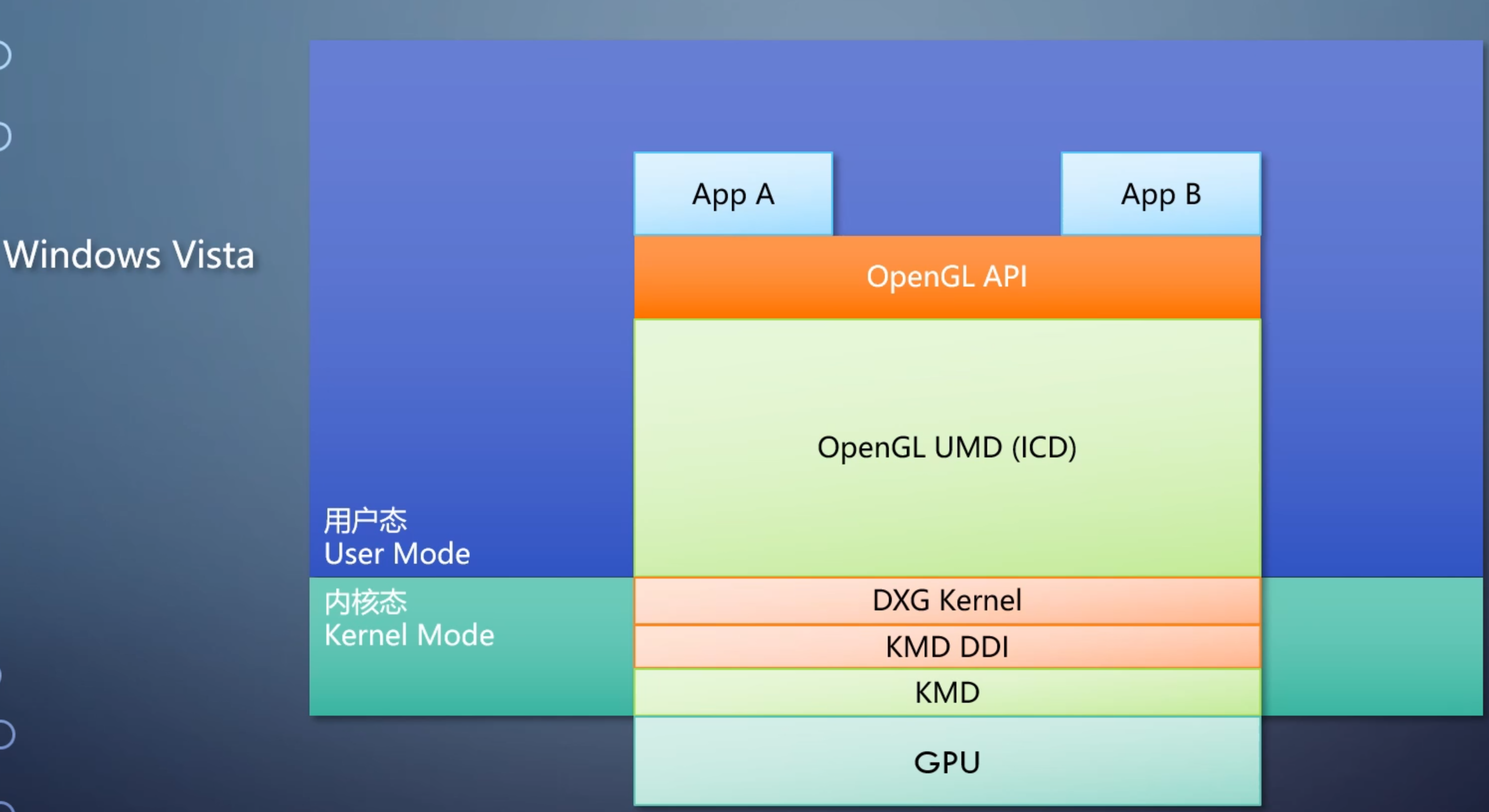
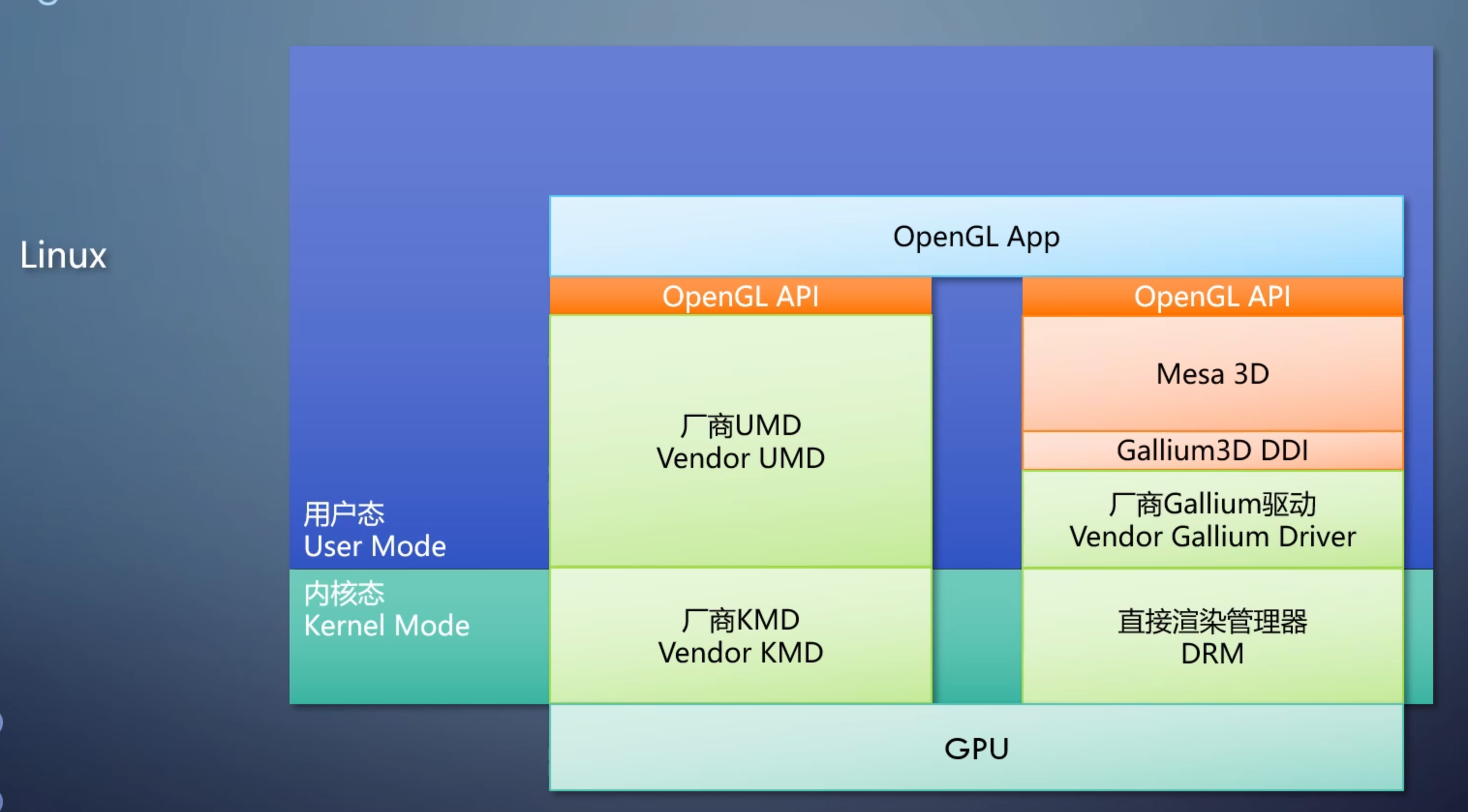
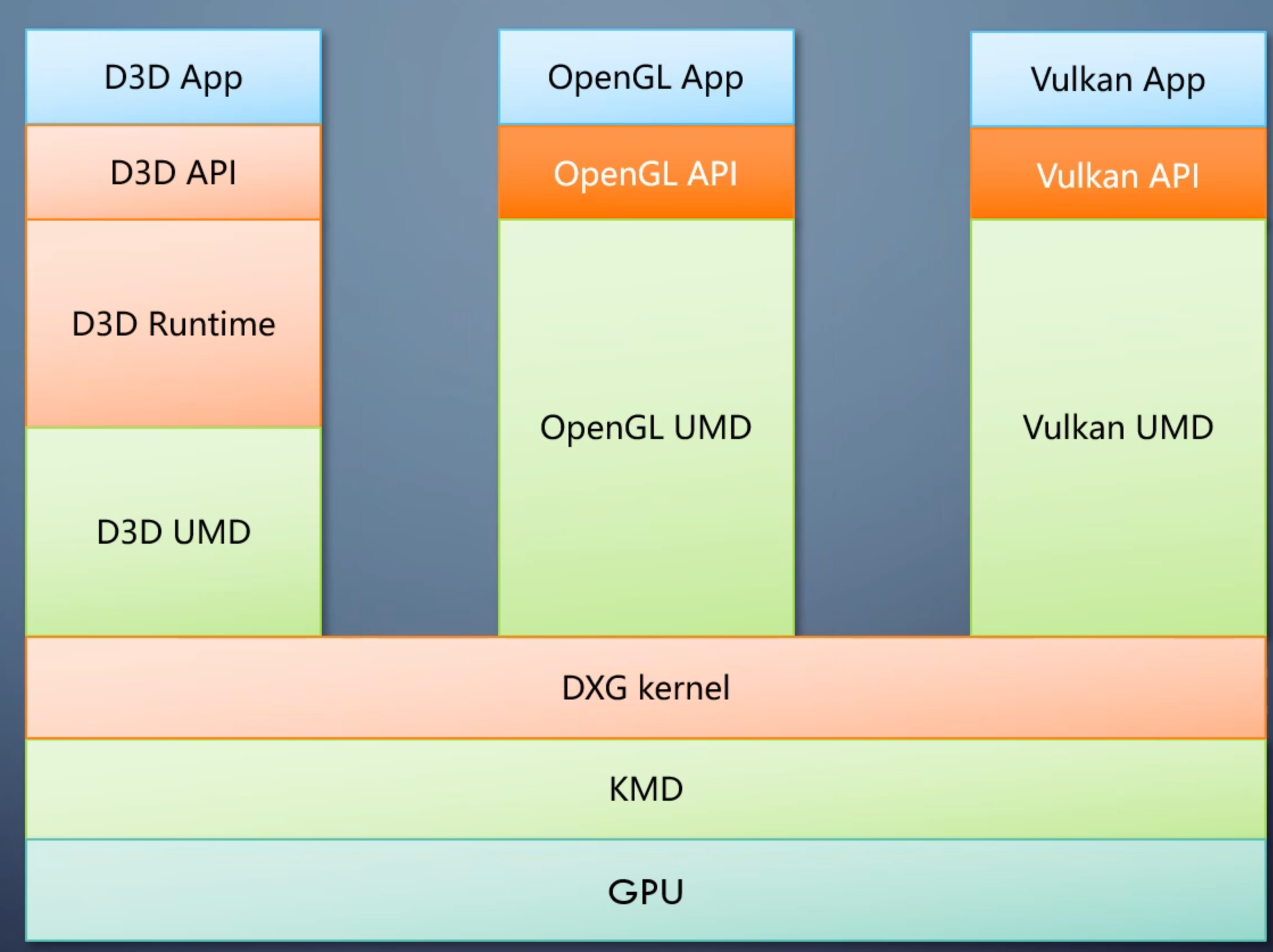
GPU 执行的是驱动发来的操作,并不知道来自于哪个API。所谓GPU支持哪个API指的是GPU厂商提供了哪个API的驱动。所以GPU支持什么API的什么功能都取决于驱动。
API和操作系统也高度相关,不同操作系统驱动不一样,换一个操作系统就得重写一遍驱动。
https://www.bilibili.com/video/BV1u3411M72A
抗锯齿
对信号的采样频率不够,就会走样,那么锯齿可以简单分为:
- 几何层面锯齿:是形状的锯齿,来源于对几何三角形边缘的采样不足。
- 着色层面锯齿:是颜色/明暗的锯齿,来源于对着色计算结果的采样不足。
那么一些抗锯齿技术就很好理解了:
- SSAA、MSAA:提升空间采样频率,可以解决几何层面锯齿。
- TAA:在时间维度上进行采样,并通过累积和重建,达到与提升空间采样频率相同的目标——获得更高频的信号信息以消除走样。
- FXAA:先低通滤波平滑信号,再进行采样。
为什么MSAA与延迟渲染不好兼容
延迟渲染会先将场景信息离散到一个GBuffer里,此时场景的几何信息被离散化处理掉了,而MSAA是通过提升空间采样频率来实现的,比如是4个采样点,那么就只能对GBuffer里每个像素分为四个采样点分别去算着色来提升采样频率,这样等于退化到SSAA,或是更大的GBuffer。并且MSAA一般有硬件协同。
Mipmap与各向异性过滤
如果一个像素对应一大块纹素,那么此时相当于采样频率很低,但是信号(每块纹素信息)却很剧烈。所以我们也可以先低通滤波,即通过卷积让信号变得平滑,再采样。有效解决欠采样。
渲染方程和蒙特卡洛
把三维信号等价于渲染方程,蒙特卡洛方法则是采样手段
光谱渲染
光谱无疑更复杂更接近现实世界,从光谱计算后的结果降采样到屏幕RGB像素,无疑质量更高。